LSTM + Kalman 分层融合自瞄:5 帧预判 20 帧的高精度坐标预测
LSTM + Kalman 分层融合自瞄:5 帧预判 20 帧的高精度坐标预测
BruceLee1. 背景与目标
在自瞄/跟踪场景里,我们希望只用前 5 帧 ROI,就能给出第 20 帧的边界框 (x, y, w, h),而且:
- 精度高:R² 接近 1,MSE 够低。
- 实时:端到端毫秒级。
- 稳定:遮挡、噪声、尺度变化下抖动小。
本文记录的方案把 LSTM 的时序感知和 Kalman 的稳健估计分层融合,同时保持极轻的推理开销。
2. 系统总览
1 | 视频帧 → YOLO 检测 → 64×64 ROI+上下文 → LSTM 时序编码 |
- 输入:5 帧 ROI(灰度 64×64 展平 4096 维)。
- 训练:20 帧序列(5 输入 + 15 间隔 + 1 目标)。
- 推理:仅需 5 帧,直接输出第 20 帧坐标。
3. 关键代码与设计
3.1 分层融合(门控 + 投影)
1 | class FusionModule(nn.Module): |
门控动态决定“信 LSTM 还是信 Kalman”,再统一投影,兼顾敏捷与平滑。
3.2 自适应 Kalman(可学习噪声 + 状态转移)
1 | class AdaptiveKalmanFilter(nn.Module): |
噪声与状态转移矩阵参与训练,对分布漂移更稳。
3.3 主干与双头输出
1 | class CoordinatePredictionModel(nn.Module): |
坐标头 + 置信度头分开,便于后处理/可视化。
3.4 ROI 与掩码
1 | gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) |
检测掩码 + padding 保留目标上下文,抑制背景噪声。
4. 训练与推理配置
- 输入:5 帧 ROI(4096 维),预测第 20 帧。
- 模型:hidden=128,LSTM 层=2,dropout=0.1。
- 优化:batch=32,lr=1e-3,epoch=100。
- 数据:小视频训练(
668 帧),大视频验证(7669 帧),检验泛化。 - 推理:端到端 2–3 ms(检测为主要开销,轻量化/缓存可再降)。
运行命令:
1 | conda create -n py310 python=3.10 |
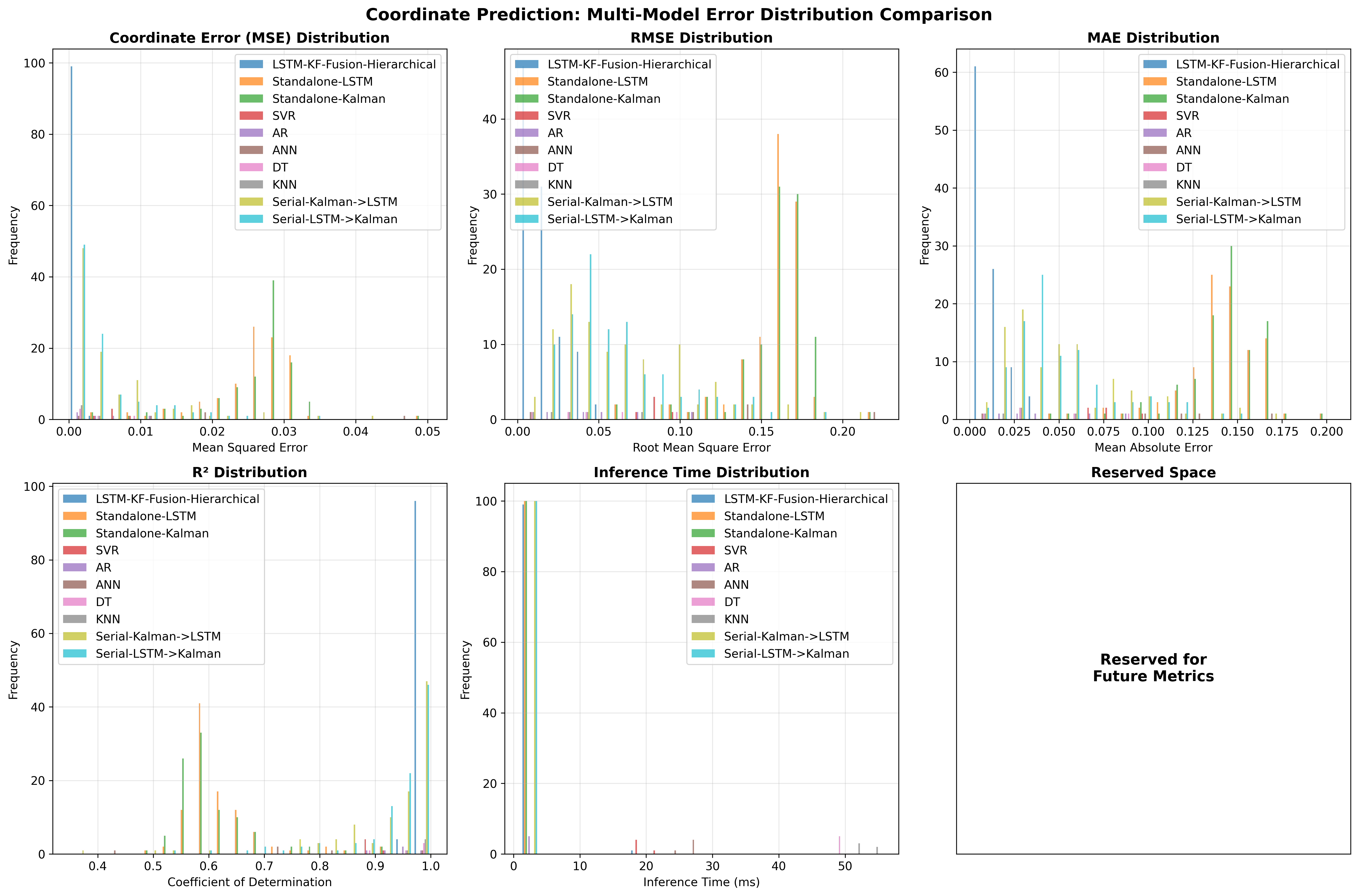
5. 结果与对比(5→20 帧)
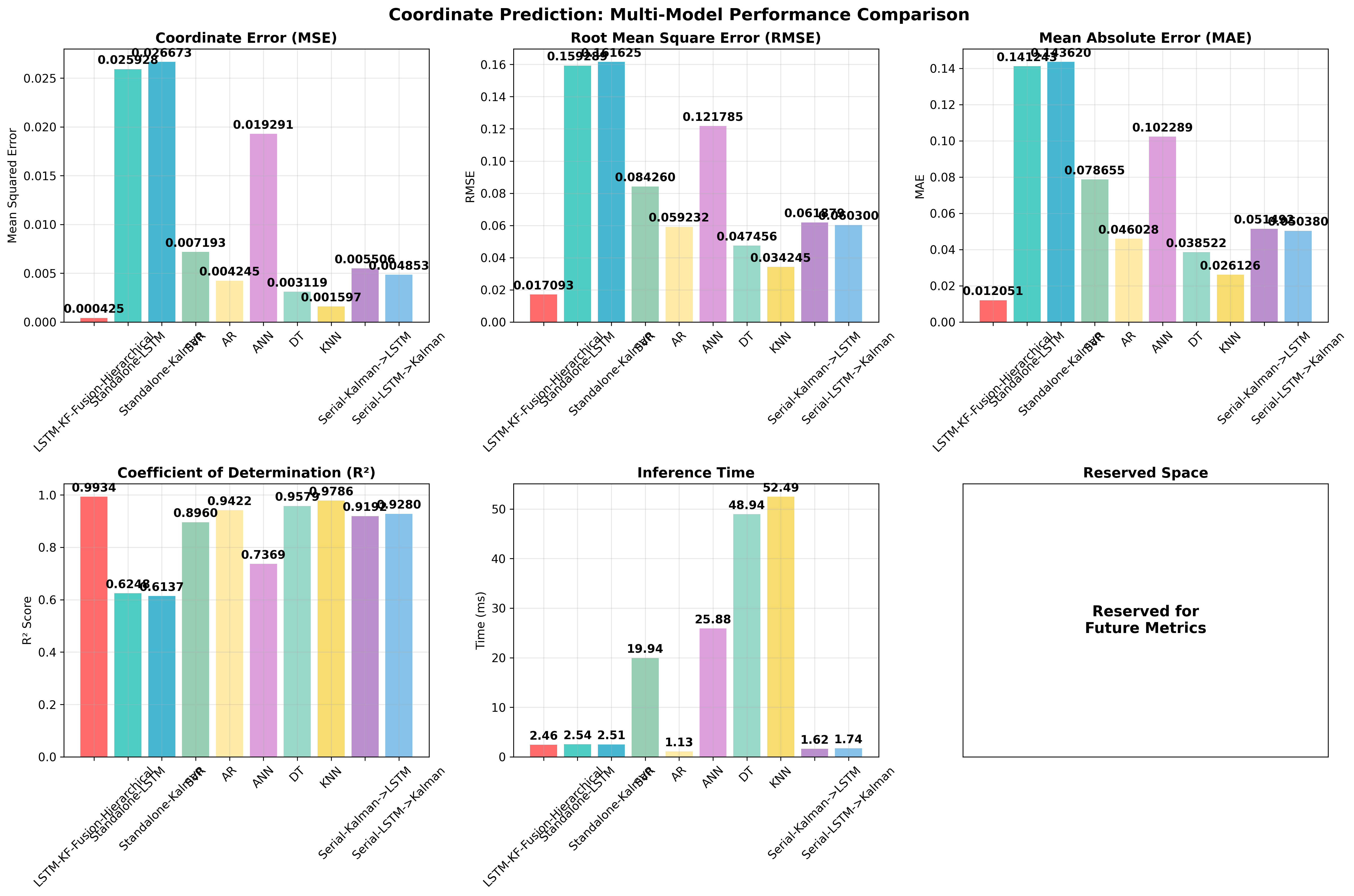
| 模型 | MSE | RMSE | MAE | R² | 推理(ms) |
|---|---|---|---|---|---|
| LSTM-KF-Fusion-Hierarchical | 0.000425 ± 0.000551 | 0.01709 ± 0.01152 | 0.01205 ± 0.00805 | 0.9934 ± 0.0091 | 2.46 ± 1.71 |
| DT | 0.00312 ± 0.00321 | 0.04746 ± 0.02945 | 0.03852 ± 0.02869 | 0.9579 ± 0.0380 | 48.94 ± 0.11 |
| AR | 0.00425 ± 0.00347 | 0.05923 ± 0.02714 | 0.04603 ± 0.02644 | 0.9422 ± 0.0410 | 1.13 ± 0.07 |
| SVR | 0.00719 ± 0.00166 | 0.08426 ± 0.00967 | 0.07866 ± 0.01117 | 0.8960 ± 0.0131 | 19.94 ± 0.24 |
| KNN | 0.00160 ± 0.00171 | 0.03425 ± 0.02059 | 0.02613 ± 0.01619 | 0.9786 ± 0.0201 | 52.49 ± 1.88 |
| Serial Kalman→LSTM | 0.00551 ± 0.00726 | 0.06188 ± 0.04095 | 0.05149 ± 0.03431 | 0.9192 ± 0.1105 | 1.62 ± 0.18 |
| Serial LSTM→Kalman | 0.00485 ± 0.00585 | 0.06030 ± 0.03488 | 0.05038 ± 0.02966 | 0.9280 ± 0.0893 | 1.74 ± 0.19 |
| ANN | 0.01929 ± 0.01547 | 0.12179 ± 0.06678 | 0.10229 ± 0.05234 | 0.7369 ± 0.1843 | 25.88 ± 0.27 |
| Standalone LSTM | 0.02593 ± 0.00653 | 0.15929 ± 0.02356 | 0.14124 ± 0.02395 | 0.6248 ± 0.0742 | 2.54 ± 0.14 |
| Standalone Kalman | 0.02667 ± 0.00655 | 0.16163 ± 0.02346 | 0.14362 ± 0.02396 | 0.6137 ± 0.0746 | 2.51 ± 0.12 |
6. 更多细节与亮点
- 为什么要分层融合:Kalman 擅长平滑与抗噪,LSTM 擅长捕捉序列模式,门控让二者动态取长补短。
- 5→20 的设定:比常见的短期预测更具挑战,能验证模型对长跨度运动的外推能力。
- ROI + 上下文:在小目标/遮挡场景中,少量上下文能显著降低误检与漂移。
- 置信度头:可用于过滤低置信度预测,或在可视化中用透明度/颜色区分。
7. 消融与经验
- 去掉 Kalman:MSE 上升一个数量级,远期抖动明显。
- 去掉融合门控:快变/遮挡下不稳,误差方差增大。
- 关闭上下文 padding:小目标易漏检,R² 明显下降。
- 序列长度减到 10:实时性更好但远期精度显著下降。
调参提示:
- 目标小且易抖:增大 padding,抬高置信度阈值。
- 剧烈运动:放宽 Kalman 噪声初值或增大 hidden。
- 部署:检测是瓶颈,先轻量化/缓存检测;融合头极轻,可 ONNX/TensorRT。
8. 复现路线
- Python 3.10,安装依赖:
requirements.txt+scikit-learn joblib scipy pandas tqdm seaborn。 - 放置视频与
best.pt权重。 - 训练:
python train_coordinate_prediction.py。 - 演示:
python coordinate_prediction_demo.py生成三列视频(原始/检测/预测)。 - 评测:
python coordinate_prediction_comparison.py自动产出表和图。 - 无 GPU:降低
num_sequences与sequence_length,逻辑仍可跑通。
9. 结语
分层融合让 LSTM 的时序感知与 Kalman 的稳健估计互补,在“5 帧看穿 20 帧”的自瞄任务里兼顾了精度、延迟与稳定性。接下来可以尝试多尺度金字塔、检测-预测联合训练,以及端侧加速(多线程解码 + 轻量化检测)进一步压榨时延。


评论
匿名评论隐私政策
🎓 大学生知识博客

🐶
BruceLee
生活明朗,万物可爱
这里分享计算机科学、算法学习、编程技巧和学术研究心得。涵盖数据结构、Web开发、机器学习等领域的学习笔记和实践经验。希望能与同样热爱学习的朋友们一起进步,共同探索技术的无限可能。





