三天血泪史:我在RTX 4060上部署DeepSeek R1的完整指南

三天血泪史:我在RTX 4060上部署DeepSeek R1的完整指南
BruceLee三天血泪史:我在RTX 4060上部署DeepSeek R1的完整指南
前言:为什么我要选择本地部署?
最近大语言模型很火,但用API总有种”受制于人”的感觉,同时还常常遇到高峰期请求失败的情况。作为一名开发者,我决定在自己的电脑上搭建一个完全本地的AI助手。没想到,这个决定让我开始了72小时的”渡劫”之旅…
硬件环境检查
我的配置:
- 💻 拯救者R9000P ARX8
- 🎮 NVIDIA RTX 4060 Laptop GPU (8GB VRAM)
- 🧠 16GB DDR5 RAM
- 🐧 Ubuntu 24.04 LTS
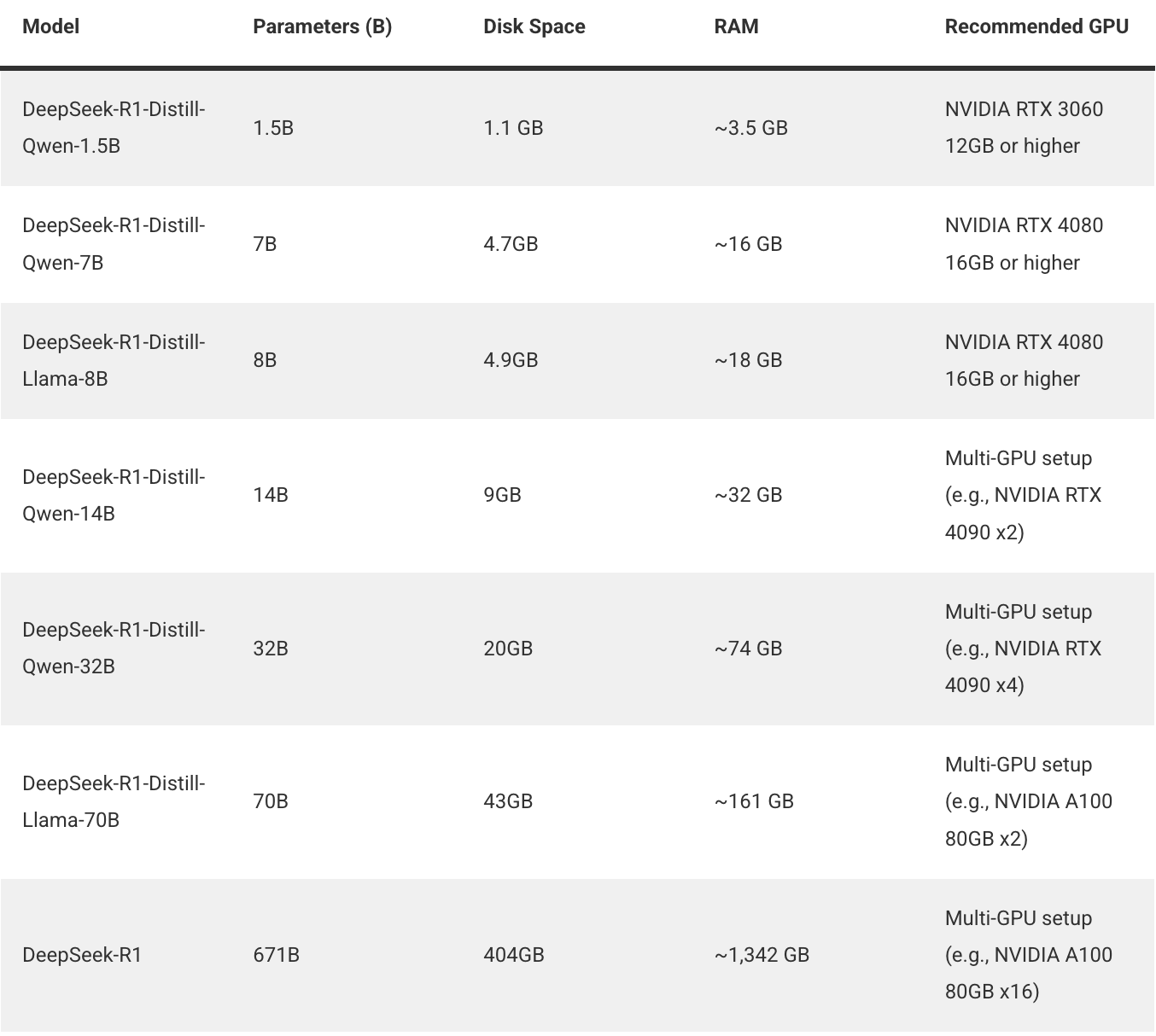
DeepSeek R1 模型参数与显卡需求(来自官方文档)
第一阶段:正确的部署流程(避坑版)
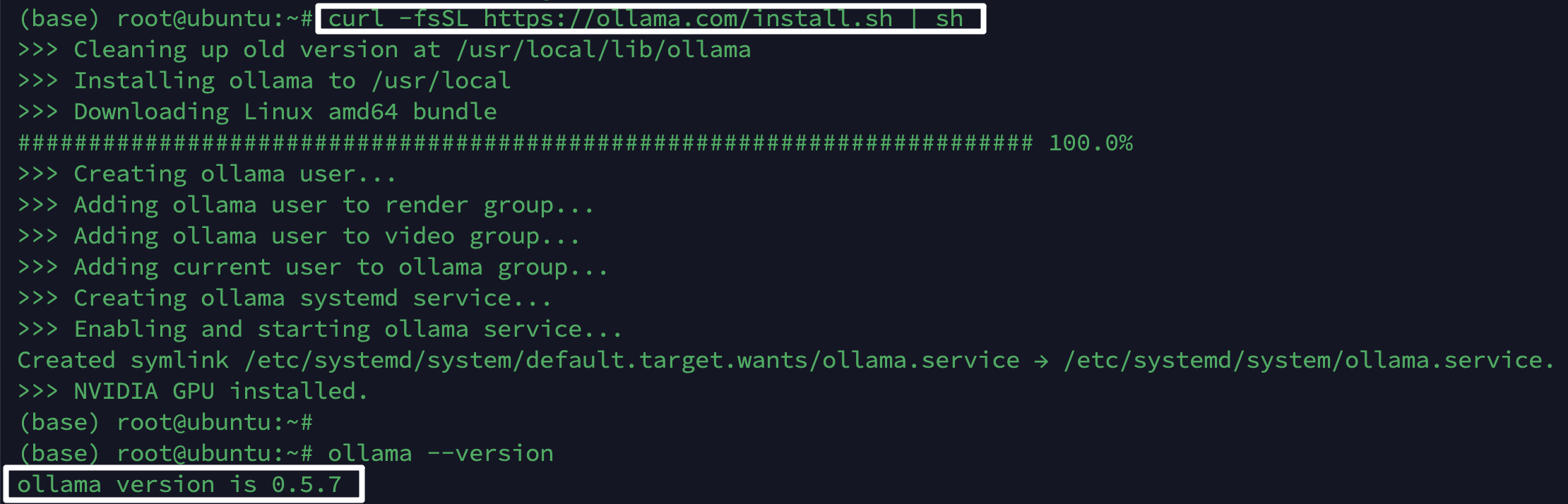
1.在 Ubuntu 上安装 Ollama
官方方法(网络好时推荐):
1 | # 一键安装 |
离线安装(我的实际方案):
1 | #1. 下载离线包(在其他机器上) |
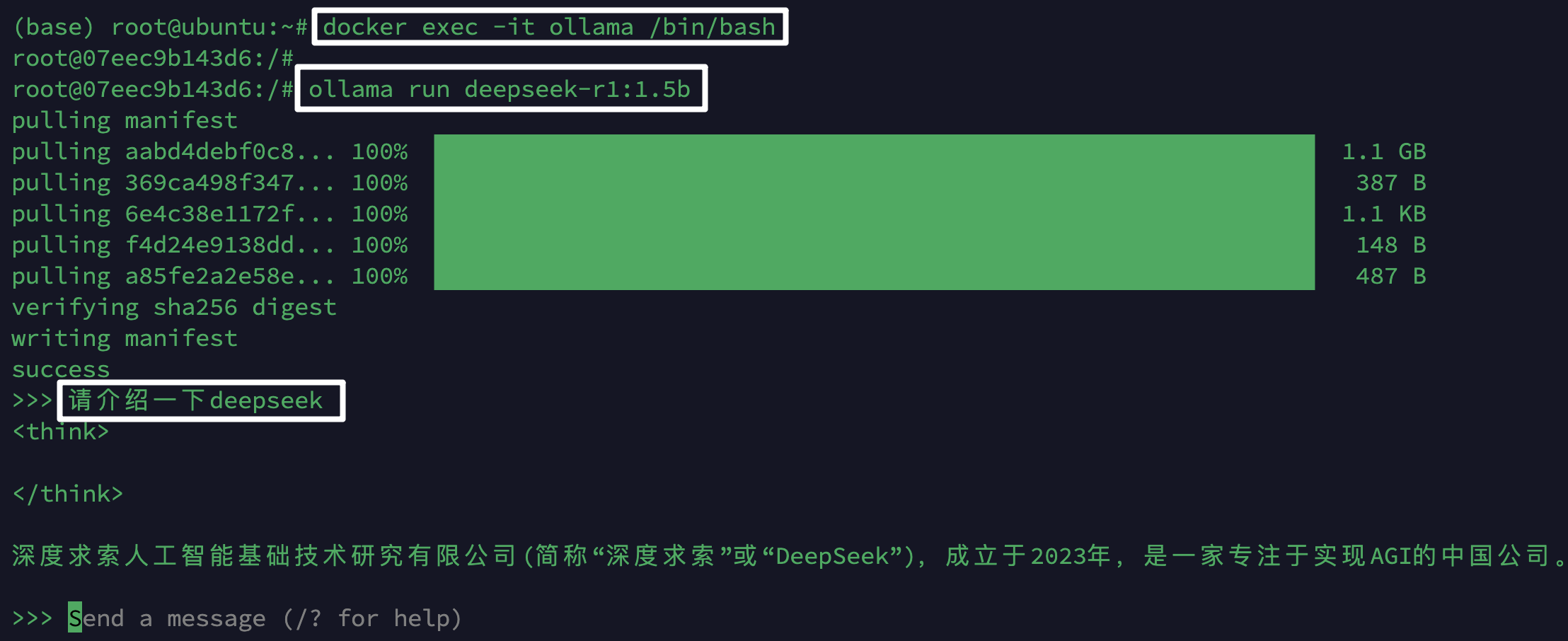
2. 下载DeepSeek R1 模型
1 | #直接运行会自动下载 |

3. Docker部署(GPU版本)
步骤1:安装NVIDIA容器工具包
1 | # 添加NVIDIA包仓库 |
步骤2:拉取Ollama Docker镜像
1 | # 使用可用镜像源 |
步骤3:运行ollama
1 | docker run -d \ |
4. OpenWebUI部署与交互
1 | # 参考链接:https://github.com/open-webui/open-webui.gi |

1 | # 3. 启动 ollama docker 模型服务 |
第二阶段:我踩过的坑和解决方案
坑1:网络限制导致安装失败
问题现象:
1 | # 一直卡住或者报错 |
尝试的解决方案:
- ❌ 换国内源(发现没有Ollama的源)
- ❌ 配置HTTP代理(公司网络限制)
- ❌ 手机热点(速度太慢且不稳定)
- ✅ 离线安装:下载离线包+U盘传输
坑2:模型下载中途失败
问题现象:
1 | ollama run deepseek-r1:1.5b |
解决方案:
- 发现Ollama支持断点续传,重复执行即可
- 选择网络较好的时段
- 耐心重试了3次才完成
坑3:Docker GPU支持问题
错误信息:
1 | docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. |
根本原因:缺少NVIDIA容器工具包
解决过程:
- 先安装NVIDIA驱动:
1
sudo apt install nvidia-driver-550
- 然后安装容器工具包(见前面正确步骤)
- 验证:
docker run --rm --gpus=all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
坑4:Docker镜像拉取失败
问题:国内镜像源大面积停止服务
1 | docker pull ollama/ollama |
解决方案:
- 尝试阿里云、网易、中科大镜像,都失败
- 最终找到可用的私人镜像源:
docker.1ms.run/ollama/ollama
坑5:端口冲突
问题:11434端口被占用
1 | docker: Error response from daemon: Ports are not available: listen tcp 0.0.0.0:11434: bind: address already in use. |
解决方案:
1 | # 查找占用进程 |
第三阶段:最终效果与性能测试
成功部署后的界面
访问 http://localhost:8805 可以看到:
- 🎨 漂亮的聊天界面
- ⚡ 实时响应
- 📁 对话历史管理
- ⚙️ 模型切换功能
实际对话测试
我:请解释一下PPO强化学习算法
DeepSeek-R1:PPO(Proximal Policy Optimization)是一种策略梯度算法,它通过限制策略更新的幅度来保证训练的稳定性。主要优点是实现简单、效果稳定、适用于连续和离散动作空间…
经验总结与建议
给新手的建议
- 硬件选择:8GB显存老老实实用1.5B模型,别想7B
- 网络准备:提前下载好离线安装包
- 镜像源:多准备几个备选源
- 耐心:模型下载很耗时,做好心理准备
必备检查清单
- NVIDIA驱动已安装 (
nvidia-smi有输出) - Docker已安装 (
docker --version) - NVIDIA容器工具包已安装
- 11434端口未被占用
- 磁盘空间充足 (至少10GB)
性能优化技巧
1 | # 调整Ollama的线程数 |
未来计划
- 接入本地文档:实现真正的RAG功能
- 尝试微调:用自己数据训练专业模型
- 优化部署:使用Docker Compose管理
- 监控系统:添加性能监控和日志
结语
这72小时的部署之旅虽然曲折,但收获巨大。从一次次失败到最终成功,每个错误都让我对Linux、Docker、GPU驱动有了更深的理解。现在我的本地AI助手已经稳定运行,这种”一切尽在掌握”的感觉真的很棒!
如果你也想在本地部署大模型,希望我的经验能帮你少走弯路。记住:每个错误都是成长的机会,坚持下去一定能成功!
资源下载:
欢迎在评论区分享你的部署经历和问题!


喜欢这篇文章的人也看了


评论
匿名评论隐私政策
🎓 大学生知识博客

🐶
BruceLee
生活明朗,万物可爱
这里分享计算机科学、算法学习、编程技巧和学术研究心得。涵盖数据结构、Web开发、机器学习等领域的学习笔记和实践经验。希望能与同样热爱学习的朋友们一起进步,共同探索技术的无限可能。